Mina gästbloggar i marsresp majgick in på nyanser av koppling mellan klasser (på gränsen till avancerad UML), som resulterar i länk mellan objekt (pekare, referens, främmande nyckel, nästlat objekt mm).
Vid första anblick tycks hanteringen av härledda värden (jfr. kurs T2715Agil modellering med UML) vara en hårfin nyans i jämförelse, men för arkitekten kan den bli en liten tuva som stjälper ett BigData-lass. Skall man göra härledda värden till attribut – eller hellre till utparametrar från de beräkningsoperationer som härleder dem? Det korta svaret är ”beror på”, men den som sysslat med dataintensiva system länge anar redan på vad:
– Hög andel frågor (eller gott om billigt minne/cache) talar för separat attribut, och i CQRS även separat klass, komponent, eller system för frågehantering.
– Hög andel uppdateringar (eller gott om billig processorkapacitet) talar för beräkning även för att besvara frågor – där frågorna är tillräckligt sällsynta kan man leva med en tillfälligt längre processorkö (enda sedan nätverksdatabaser har det funnits specialvarianter av datatyp för detta, Codasyl-standarden som var ”preSQL” snarare än noSQL erbjöd typen ”result of procedure XY” ). Med andra ord är de två viktigaste nyckeltalen som styr beslutet:
1. marginalkostnad för processorkapaciteti relation till dito för minne
2. förväntad andel frågor (CQRS-Q:et) i relation till förväntad andel uppdateringar (C:et).
Och skillnaden mellan attribut och utparameter i UML? Även här är svaret ”beror på…”
Anta som ett exempel att Produkt i vårt system har ett tillverkningsdatum och en ålder (ålder= maskindatum och tid minus tillverkningsdatum och tid). Tillverkningsdatum uppdateras aldrig i normalfallet, och blir ett attribut, men ålder ”beror på”: om den mäts i t ex månader så blir andelen uppdateringar mycket låg, vilket talar även för ålder som attribut:

Bild 1 – ålder som attribut.
Om åldern däremot mäts i driftssekunder, av ett litet chip ombord med begränsad kapacitet, och läses sällan, t ex av serviceutrustning i hangaren/depån, så lutar det åt en utparameter i stället. Då går det att låta ett annat system på en server beräkna åldern (t ex ur start- och stopptider i loggfiler) den gången något anrop verkligen frågar efter den. Det vanliga sättet att visa utparameter i UML är efter ett kolon:

Bild 2 – utparameter (vanligast).
Men det finns ett mindre vanligt sätt också. Ett snedstreck visar att värdet är just härlett dvs inte lagrat som vanliga attribut:
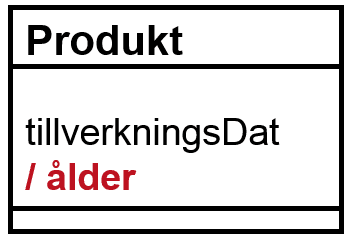
Bild 3 – implicit utparameter (härlett värde).
I agil modellering låter vi mottagarens informationsbehov styra. Om ritningen vänder sig primärt till kravställare eller analytiker, är det enklast för alla att vara konsekvent med inkapslingen och dölja även (den i deras ögon hårfina) skillnaden mellan ”vanliga” attribut och härledda. Däremot om arkitektrollernaär involverade (DBA, SA/SWA, produktarkitekt, osv) blir skillnaden mycket viktigare då den inverkar på tradeoffs mellan olika kvalitetskrav (NFR).
konsult, Kiseldalen.com
UML 2 Professional, OCUP Advanced Level (certifikatnivå 3 av 3)
Huvudförfattare UML Xtra Light: How to Specify Your SW Requirements
Milan samarbetar med Informator sedan våren 1996 inom modellering, UML, arkitektur, krav, analys och design. Håller f.n. kurser i Arkitektur, i modellering (T2715, T2716), och 2013 höll han också Informators fullsatta Frukostseminariumom användningsfall.