
Health, pharma, and care expose Machine Learning to yet another stress test in practice, which adds another vital quality attribute to architects’ QA-list (along with explainability, security, safety, accuracy, etc.) – privacy-friendly ML.
Three current examples from the health realm
1. Most public authorities worldwide are using outdated analytics tools in forecasting and warning. Canadian AI-based warning system BlueDot predicted the corona epidemic , and where it would travel to next. It was weeks ahead of the WHO (not to mention China: just scroll down on BBC News, to “An epic political disaster”). The persecuted and deceased whistleblower Dr Li Wenliang’s words “A healthy society should not only have one voice” happen to reflect a universal principle worth considering in architectures as well. To pick a handful: Triple Modular Redundancy (in mission-critical onboard systems etc.) , P2P (Peer to Peer architecture pattern), SOA, decision forests, and not least, Federated Learning (FL, see below). The more “biodiversity”, the more robust, fit, and sustainable the outcome; be ecosystems, social systems, public health systems, or ML-driven systems.
2. AI-based selftests for elders will provide early warnings to persons at risk of cognitive disorders. An R&D project at the Blekinge Institute of Technology will save time and resources by cutting lengthy diagnostics procedures from months/years to hours. It’s learning from a 20-year long series of relevant data about 10,000+ persons. The Nordic region is suited for medical ML, because data from long-term studies is available about several diseases. Often, the data spans decades, yet with a relatively small drop-off.
3. Pattern recognition in image-based diagnostics. Another R&D project at the Karolinska Institute in Stockholm is using mobile solutions and AI to make medical diagnostics accessible geographically & organizationally, safe, and accurate for several diseases: ML is learning to recognize cancer, malaria, schistosomiasis (bilharzia), soil-transmitted infections, pneumonia, or to classify burns.
Privacy matters to both individuals and policymakers. Patient data takes privacy requirements an order of magnitude higher than online advertising or recommender engines did.
In addition to privacy, Federated ML (FL) addresses even security, access control, running or testing some nodes while training others, and learning from multiformat multitenancy data. A current paper by Ericsson Research also points out that FL can reduce the size of training data needed, as well as the necessary transfers and thus network footprint in runtime (by up to 99%). This is sweet music for architects. So, how is FL orchestrated?
First, let’s step back to decision forests (see last diagram and paragraph of this post), which use a simpler and more transparent distributed logic where independent decision trees are logical units (and in distributed environments, they might even correspond to HW/MW units); however, the interactions (see Sequence Diagram) are one-way. Instead of sending (sensitive) training data, each node sends its decision (sometimes with a probability value) to the center. The center counts these as “votes”, to select a “winner” decision (sometimes using probabilities as weights of each tree’s “vote”), which in turn becomes the output of the forest.
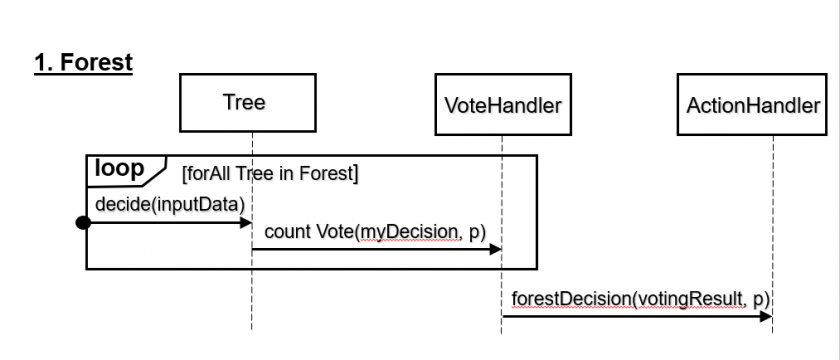
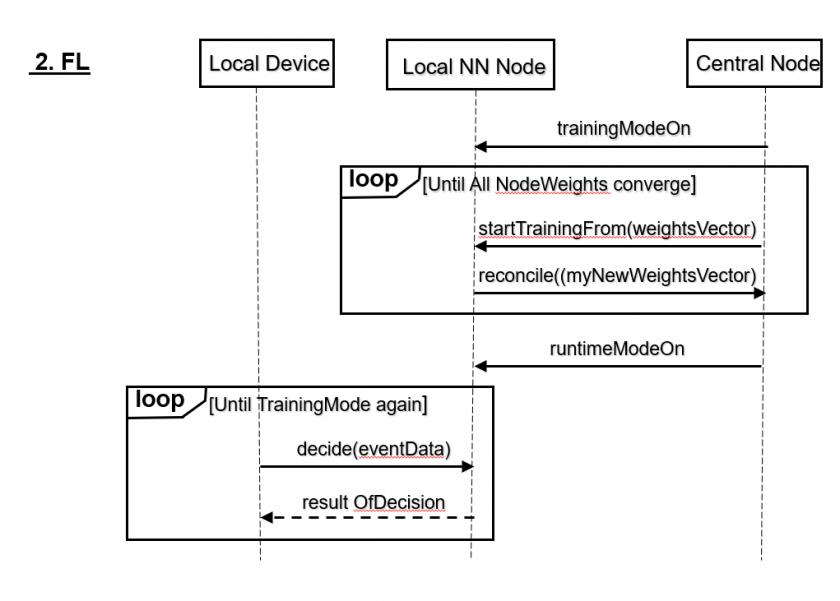
FL can use a similar topology, where edge devices or servers become nodes, but interactions (see Sequence Diagram) go in both directions. The Ericsson team put it a similar way a multimodel-database vendor in big data probably would: “bring the computation to the data”. Instead of bringing data (sensitive, especially in health) to a central node, FL trains an algorithm across several decentralized nodes that own their training data locally, without sharing it.
This results in a number of local models. These are sent (as vectors of weights) to the central node and reconciled there, into a common model (but extended algorithms can reconcile even within a Peer-to-Peer pattern). Then, this common weight vector is sent back to all nodes, each node upgrades its (neural) weights, and resumes the learning at this new level.
This learn-reconcile-update loop is repeated until the weights converge across nodes. Instead of the sensitive training data, only (intermediate) results of each training round are thus sent back and forth, as weights.
We can expect some new “mixed flavors” in a near future to borrow features across ML techniques, such as NN-based leaf nodes (from soft trees) or neural decision forests.
FL combines the privacy of local ownership of data with the accuracy built by ML from big data. Along with explainability and accuracy, privacy is essential in health apps of AI. This is one of the main reasons why FL is more viable than big-data transfers. Even more so in the EU/EES marketplace, where tech firms soon need to meet new EU requirements on AI/ML and big data.
Milan Kratochvil
Trainer at Informator, senior modeling and architecture consultant at Kiseldalen’s, main author: UML Extra Light (Cambridge University Press) and Growing Modular (Springer), Advanced UML2 Professional (OCUP cert level 3/3). Milan and Informator collaborate since 1996 on architecture, modeling, UML, requirements, rules/AI, and design. You can meet him in the coming months at public courses (in English or Swedish) onAI, Architecture, and Machine Learning
Modular Product Line ArchitectureAvancerad objektmodellering med UML
Agile Architechture Fundamentals Agile Modeling with UML