
“Today, professionals get trained in using tools… there’s a lack of education of fundamentals like modeling, architecture, methods, or concepts… Getting value out of data needs professionalization based on education and practical experience.”
In my opinion, he’s spot on.
My post from March mentions why new AI languages aren’t exactly heavies of a CV in a mainstream business; in April, a figure (at the end of the post) also touched on Forest structures in ML and eXplainable AI.
After a free-wind sail that took us from detail to architecture, we now go into some structural “forestry”. It’s about tackling the same domain from multiple viewpoints, instead of clinging on to one.
1. Multiple trees in UML: Generalization sets
My post from 2015 (in Swedish) discusses the sets in more detail, so let’s just recap the diagrams, in English, and add «powertype» on the fourth one (a power set’s instances are subsets, so by the same token, a UML2 powertype’s instances are “subtypes” of a general construct).
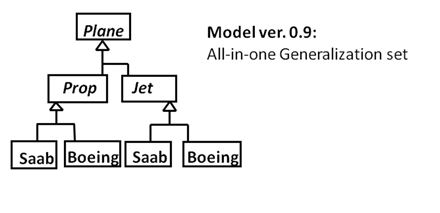
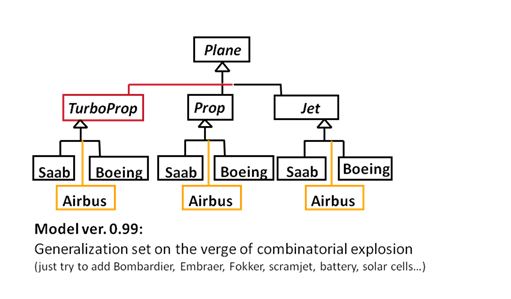
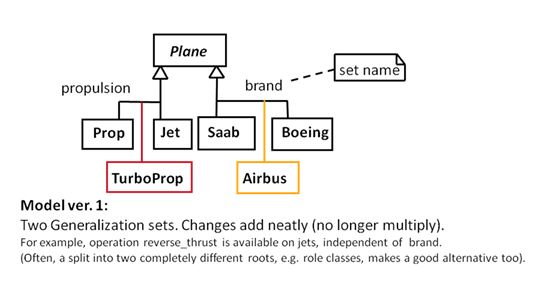
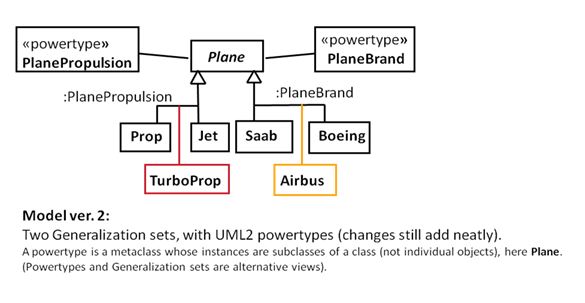
2. Multiple trees in Machine Learning: random Decision Forests
Here, a designer is not the one who maps out subclasses. Rather, an ML algorithm generates in training time, from (labeled) data, an ability to perform classification (i.e accurate “mapping-out” of “classes”). The decision nodes of a (classification) tree gradually subdivide the data into more and more fine-grained classes.
Why bother about decision trees when Deep Neural Networks are booming? Because explainability opens the door to acceptance in mission-critical apps. ML-generated logic has to be auditable. User enterprises are pushing for graphicness, conceptualization, traceability, V&V. Those are the strengths of decision trees, and weaknesses of Deep NNs (we know those work, but hardly how); same thing with learning time required, size of training data sets, execution speed, or partitionability (a hint for IT architects: a tree works independently, whereas a neuron relies on many other ones). Atop of that, decision trees offer a structural backbone of hybrid AI systems (see also the last paragraphs in this post).
You might remember that trees in woods sometimes fuse their roots and exchange materials. Unsurprisingly, we find some synergy in virtual forests too. Firstly, our trees are “grown” on a random sample each (hence some “biodiversity” too), from one training-data set (hence fewer terabytes of training data). Secondly, on each sample, its tree’s decision nodes use a random subset of all available attributes. This gives architects and other roles some room to tune the mix of efficiency and explainability; in forests, it’s is near the level of genetic algorithms (GAs too have possible “mix-tuning points” in “biodiversity steps” Crossover and Mutation).
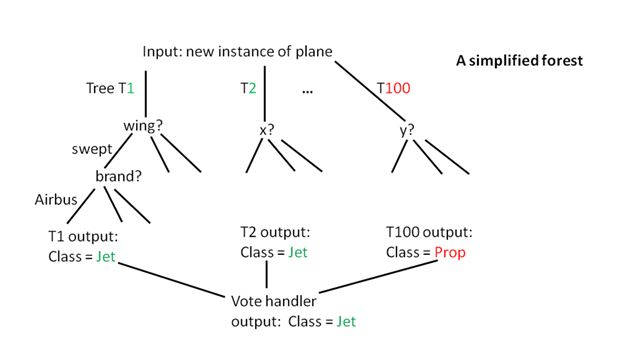
The more trees and “biodiversity” our ML algorithm grows, the more accurate and robust the generated logic becomes, because the final step is vote counting. A forest’s output (a classification like here, or a forecast) is an aggregated value of the outputs of all trees (a statistical mode in classification, or a mean in regression). It prevents the random decision forest from getting stuck in local optima, that is, we minimize error rates and overfitting to a given training-data set (which may be both incomplete and biased).