AI
Learning for AI, and the other way too

A quote from neither Informator nor Tieturi, but from the Lancet medical journal, April 2021: “particularly deep learning, has changed our lives (…) deep learning systems capable of diagnosing skin cancer and fully autonomous AI approved for diabetic retinopathy screening (…) A key concern is how should clinicians be educated in these advances and what roles they will assume in developing, validating, and implementing these technologies.”
An enterprise architect or training provider could hardly put it better, while Med and pharma continue to drive a lion’s share of new AI.
Bilinguality in terminology
Having said that, let’s keep in mind it’s a two-way street between two communities (medical & pharma, and AI & IT architecture) including some tricky “jargon bilinguality” on both sides, as is often the case in other domains too. Researchers, financial analysts, regional government authorities, power-grid planners, rail operators, and on it goes, are generally proficient in (and thus biased toward) classical statistics and its lingo whereas the straggly roots of appliedAI-ish, aged 65+, span across business rules, data/computer science, symbolic reasoning and object orientation, “subsymbolic” representations, explainability, knowledge management and elicitation, informatics, logic, set theory, search algorithms, and a dozen more.
Although much of the machinery underlying AI, including ML (Machine Learning) and neural networks, uses statistics-based methods, it does so in an own non-classical way. During the first Covid wave in 2020, California governor Gavin Newsom told CBC News: ”It’s not a gross exaggeration when I say this – the old modeling is literally pen-to-paper in some cases. And then you put it into some modest little computer program and it spits a piece of paper out. I mean, this is a whole other level of sophistication and data collection (…) We are literally seeing into the future and predicting in real time, based on constant update of information where patterns are starting to occur before they become headlines”. Harvard Medical School News & Research, March 2021, sees adaptive learning as a key source of value added by ML systems, “(…) they rely on adaptive learning: with each exposure to new data, the algorithm gets better (…) offering doctors accumulated knowledge from billions of medical decisions, billions of patient cases, and billions of outcomes”.
Redefine roles
This section of the “two-way street” is no less tricky than terminology gaps. It depends on the domain to be supported, line of business, number of employees, organization and enterprise architecture, degree of organizational learning, skills of the staff, collaboration culture (hierarchical or horizontal, formal or informal/lean/agile) etc. In most contexts, the key roles to upgrade in the first place are architect roles: enterprise, data, IT, where “the spider in the web” is part of the job description. AI boosts both the business and the architects’ daily work.
Frameworks and pretrained neural networks (sourced from ModelZoo, MatLab, TensorFlow, and many others), for clearly delimited tasks, provide most often a fast lane through the role-shaping section too, and thus a viable gateway for ML into a variety of professions. Typical pretrained-for tasks are translation and NLP (Natural Language Processing), classification, pattern recognition, pattern matching, or event-series pattern matching. When you’re on track, you can expect a marginal drop in output accuracy, but also a substantial plunge in lead time compared to untrained NN.
A quick glance inside retraining the pretrained
The weight values in neurons of an untrained neural network are initiated to random values, whereas in a pretrained network, they’ve already “smart” values learnt from many training runs on large datasets. You only train them on the delta, i.e data values that are typical of your particular subdomain. One subdomain (at a time), whenever a (back-prop) NN uses “catastrophic forgetting, CF” during retraining. For example, although your human brain didn’t forget about your piano keys while learning, say, the keyboard of your PC, your re-trained NN would forget a lot. In a nutshell: the retraining would overwrite weight values that differ from its initial piano version (over the past few years however, methods to mitigate CF improved). Hence an architect’s rule of thumb: as long as there’s considerable CF, keep the NN dedicated to one subdomain each.
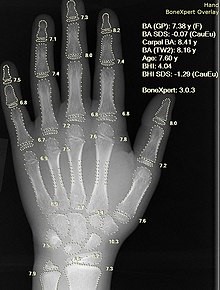
X-ray with automatic calculation of bone age. If retrained to calculate horses’ age from teeth X-rays, we can expect quite some CF. Source: Wikipedia:
{kind=link}
Summing up: Over the past 12 months, the Covid pandemic has triggered a wave of open science, open data, open-source libraries, and open frameworks. While approximately 4,000 new publications appear daily on PubMed.gov, AI helps readers to filter the (big) data, but also to speed up and improve their research or their daily work as clinicians.
Stay safe!
Related courses:
- AI, Architecture, and Machine Learning
- Agile Architechture Fundamentals
- Agile Modeling with UML
- Avancerad objektmodellering med UML
- (on demand: Modular Product Line Architecture
Trainer at Informator, senior modeling and architecture consultant at Kiseldalen’s, main author: UML Extra Light (Cambridge University Press) and Growing Modular (Springer). Advanced UML2 Professional (OCUP cert level 3/3).
Milan and Informator collaborate since 1996 on architecture, rules, AI, modeling, UML, requirements, and design. You can meet him this year at public courses, in English or Swedish (remote participation is offered, encouraged, and currently highly recommended by epidemiology experts).
